<aside> 📝 2024年12月02日 16:51:08
使用过笔记类软件的朋友都知道,这位朋友遇到的可能是一个共性问题,也就是:我们自己的笔记究竟该如何处理才最方便、最有助于个人成长?不同的软件有不同的理念,有的服务注重开放性,能够与市面上的其他服务共通,便于定制自己的知识空间;有的软件则认为自己的知识整理理念独一无二且非常优秀,因此相对封闭,便于吸引用户且留住用户。
</aside>
<aside> 📝 2024年12月02日 16:51:21
针对笔记和知识整理领域,我们来共同探讨关于个人数据整理的问题:
<aside> 📝 2024年12月02日 16:51:51
什么样的存储方式才是「好」的?
现在是 21 世纪,因为疫情,云服务在这两年大热。在这两年,不少云存储服务也百花齐放。但说到存储,**首先要搞清楚我们要存储些什么东西?**既然是要存,我们希望的自然是能够「在我想要的时候找到它」,减少损坏、降低遗失的几率。各家云服务为我们提供了随时获取自己数据的权利,但也带来一个问题,那就是:我们存到云端的数据,还是我们的吗?随着不少云服务供应商的政策变化,我们越来越注意到,放在云端,虽然方便获取,但也方便丢失了。靠谱的供应商还给你数据导出和备份的机会,不靠谱的,直接关掉你的账户,你的数据、记忆、情感、心血,可能一瞬间就灰飞烟灭。所以,这两年回归本地仓储的声音也越来越高。因为,放到云里,实在太不稳定了。
那么,多备份几份数据不就好了?
是这样,一个服务商丢了,我们可以从另一家获取。我的还是我的。这就是 All-in-all 的存储,安全、稳定、便利。但我们当真需要花费这么多时间和精力对自己的数据进行整理、归档、存储吗?要知道,每多存储一份,需要付出的时间、金钱也多一份。
</aside>
<aside> ⭐ 2024年12月02日 16:52:20
世界上还存在另一种服务,All-in-one 的服务,如果不能选择把数据交给所有服务商,那就交给一家放心的好了。如果说 All-in-all 的存储是一个极端,那 All-in-one 这种服务,则走向了另一个极端。前者过于耗费心思,后者则直接放弃了自己选择的权利,前者是「把每一个鸡蛋各自放在一个篮子里」,后者是「把所有鸡蛋都放到同一个篮子里」。任何一个明智的人都知道,凡事有度,走向任何一个极端都不合适。
</aside>
<aside> 〰️ 2024年12月02日 16:52:45
有人讲,我交给自己放心的服务商,良好的互联网生态下,使用起来更为便利。虽然放弃了自己选择的权利,但我获得了优质的服务,何乐而不为?
当然是的,但这种情况的前提是:我们一辈子都呆在同一条船上,不导出自己的数据。就用它好了,不需要导出,这样在任何设备,登录一个账户,就能看到自己的信息了!
看似美好,但这样做的话,我们也陷入的一定的风险,比如「某笔记」的怪圈:
这就是所谓的 数据孤岛。用得越多,沉没成本越高,越难以脱离这个工具,迁移所需要的成本也越高。
</aside>
<aside> ⭐ 2024年12月02日 16:52:57
为避免这种情况的发生,我诚挚地推荐大家构建自己的个人数据库。而且,当我们构建个人数据库时,需要仔细斟酌各项服务的优劣。依照我的个人经验,要想「避坑」,需要遵循两条原则:
<aside> ⭐ 2024年12月02日 16:53:18
当你需要查询某个内容,你的做法并不是通过搜索引擎,而是在你的「个人数据库」中,通过模糊查询,就能找到你需要的这些内容。
不仅如此,这条信息的属性(标签),以及当初加入时你写的备注,甚至于这条信息的关键内容(标注),以及出处(原文链接)等有效信息都能被迅速找到。
而这条信息要比从搜索引擎得到的内容更加专门针对于你,这就是个人数据库,一个属于你自己的信息筛选 / 查询 / 编辑整理系统。
能做到上面这点工具有很多:
<aside> 📝 2024年12月02日 16:53:44
一个良好的个人数据库
</aside>
<aside> 📝 2024年12月02日 16:53:51
首先,数据信息是数据库构建的基础,对数据加以整理形成数据库的基础在于信息标识。 **所谓信息标识,是指对信息的描述、解释和控制,一般而言,基础的信息标识包括数据的标签、备注、描述等等。**多元且丰富的信息标识使得我们对信息的检索和获取更加便利,因此,信息标识越多越好,或者讲,可添加的信息属性 / 维度越多越好。
</aside>
<aside> 📝 2024年12月02日 16:54:03
其次,既然是「个人」数据库,就要注重数据信息的「专属性」和「隐私性」。「专属性」自不必言,当我们选择信息时必然围绕着自己的相关需求展开;而对于「隐私性」,在处处实名的今天,似乎成了一个笑话,大厂围绕数据安全的论战不断,也充分体现人们对隐私的关注。
我们不追求「隐私换取便利」,但也要尽可能把隐私安全放在重要位置。You are what you read,你阅读的东西造就了你,而如果你的阅读记录被泄露,也足以分析出你是什么样的人。因此,为了追求「隐私安全」,我们应尽量选用以本地管理为主的服务,凭借本地化存储和管理方式,我们可以完全控制数据的存储方式、访问权限以及信息安全协议等
</aside>
<aside> 📝 2024年12月02日 16:54:37
单纯地看,线上服务更方便,但纯线上的服务都无法满足方便迁移这个事情,越是主打快照功能的服务越是如此。这也就发生了上文截图反映的问题:不方便迁移。为什么这样讲?
主要有以下三个原因:
其一,仅仅支持导出到本地是不够的。导出后的数据若无法与线上数据形成对应关系,就无法形成系统的知识体系。若再给导出的数据增加一条「护城河」,仅支持导出专有格式,那这样的导出本地几乎没有意义。这意味着导出的数据对我来说是不方便处理的。如果无法构建「库」,再多的本地数据也是一片散沙。因此,支持本地快照和离线存储是把数据放到自己手上,而导出的格式是什么也同样重要。
其二,**无法实现自动化方案。**我们可以导入一条数据后再手动将其导出至本地,但这样做太费时间了,如果支持自动化,何乐而不为?
其三,**后端流量消耗严重。**设想一个用户有 100MB 数据,如果有 100 个这样的用户呢?
正所谓**「导入一时爽,导出火葬场」**。
</aside>
<aside> 📝 2024年12月02日 16:54:45
鉴于不少服务增加这条「护城河」来把用户锁在城里的做法过于无耻,笔者认为,优秀的本地存储应使用公有数据结构 ,以基于文本的格式为例,如 HTML、 JSON、 Text Bundle、 Markdown 等都是良好数据结构。
</aside>
<aside> 📝 2024年12月02日 16:54:49
如果同时满足第二点和第三点,即为自由导出。可以离线 + 方便处理 ≈ 数据自有。
</aside>
<aside> 📝 2024年12月02日 16:54:52
如果支持 API 的话,可以通过各种线上的自动化平台,便利地从线上导入数据到本地。也就意味着,自己手上永远有一份数据备份。
</aside>
<aside> 💡 2024年12月02日 16:55:08
建议优先选择基于本地系统的双链笔记,如 Obsidian、Logseq 等,它们支持本地系统,并且基于文本格式,因此可以使用任意多的信息标识,方便索引,方便搜索,方便迁移。
它们可以满足个人数据库:
<aside> ⭐ 2024年12月02日 18:29:59
https://res.cloudinary.com/dvyu4sgrr/image/upload/v1732682511/simpread/4ee844619d41041ba571fd794c94b85125c2f6e5.webp
</aside>
<aside> ⭐ 2024年12月02日 17:14:23
有没有一种线上 + 线下的方案,不仅可以弥补本地仓储「不方便获取」的缺陷,也能弥补在线存储造成的「数据孤岛」?
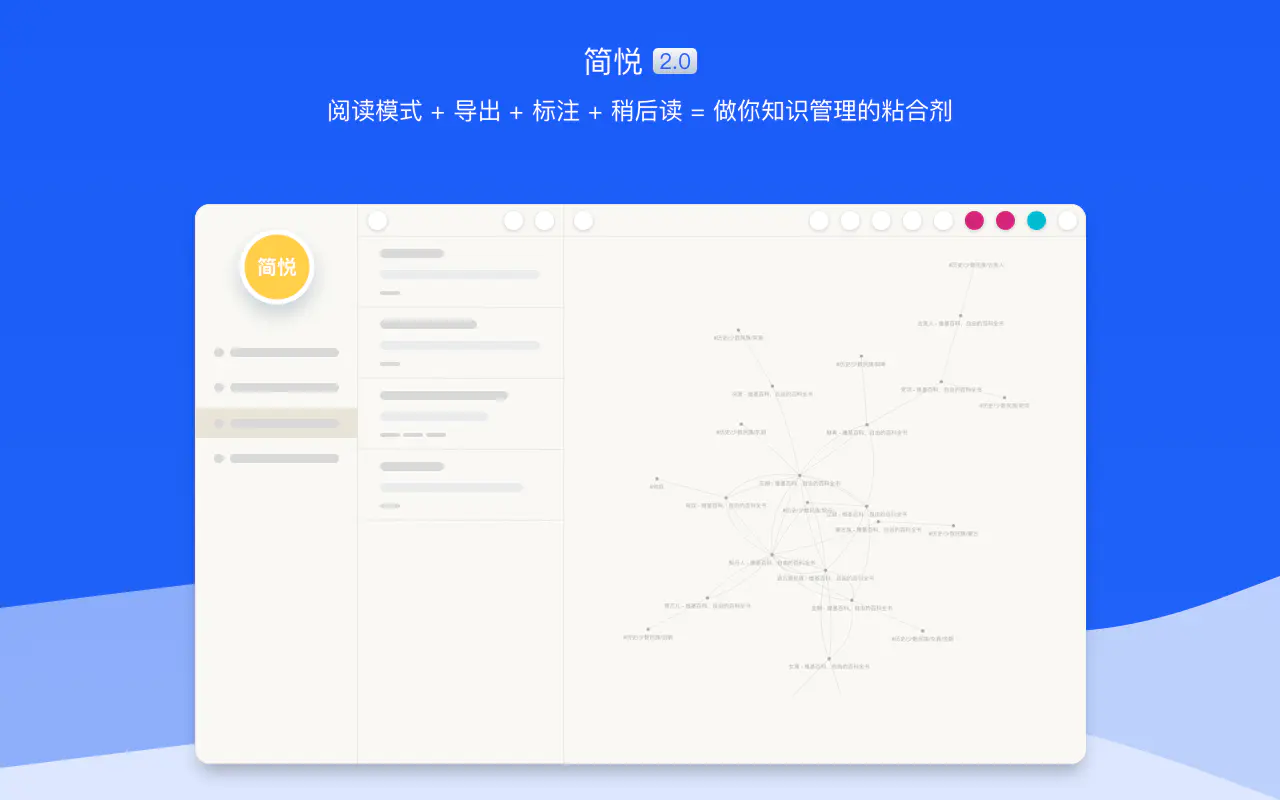
不如试试简悦吧,它几乎可以完全满足个人数据库的要求。并且,由于高度的可定制化,弥补了线上和线下服务的劣势。
简悦是什么?多数朋友从「阅读模式」或「主打沉浸式阅读体验」了解到的简悦。但简悦已经存在四年多了,为什么要在这个时候再提起它呢?在这几年的版本迭代中,我发现,**读者用户所需要的不仅仅是清爽的阅读体验,还有阅读过程的整理和思考。**我个人比较喜欢阅读,也正是因为厌烦了不规范的页面和无处不在的小广告,才开发了简悦的最初版本。但如果简悦止步于「阅读模式」,我们不必再度提及。在历次版本迭代中,**读者用户的需求各式各样,如何满足绝大多数人的不同口味?**正是这个问题引发了我将简悦转型的许多思考。
也就是说,我希望简悦可以成为大家的知识管理助手,而非单纯一个 Read Mode 插件。
举例而言,在个人数据库的管理上,基于本地系统的 Obsidian、Logseq 等工具,由于其并没有官方提供的剪藏工具(本地化服务的剪藏能力先天不足),无法从手机端便利地导入本地,而第三方的剪藏工具的效果也参差不齐。为了弥补这一点,简悦增加了这几个功能:
<aside> ⭐ 2024年12月02日 17:14:29
你可以依靠开放的互联网生态借助简悦打造自己的个人数据库,因为:
{kind=link}